
Table of content
This blog post discusses the Entropy and Cross-Entropy functions and how to calculate them from our dataset and the predicted values. The more you know about your data matrix, the more effectively you can implement the discussed methodologies. While dealing with methodologies and algorithms of Machine Learning, Neural Networks, or Deep learning models, loss/cost functions are used to evaluate and improve the model’s accuracy during the training phase.
All this effort is centric around the minimization of the loss function. The lower the loss, the more accurate and precise the model. Cross-Entropy loss is a notable cost function used to optimize classification models. Consider a 4-class classification algorithm that recognizes an image as either a car, a bike, a plane, or a boat.
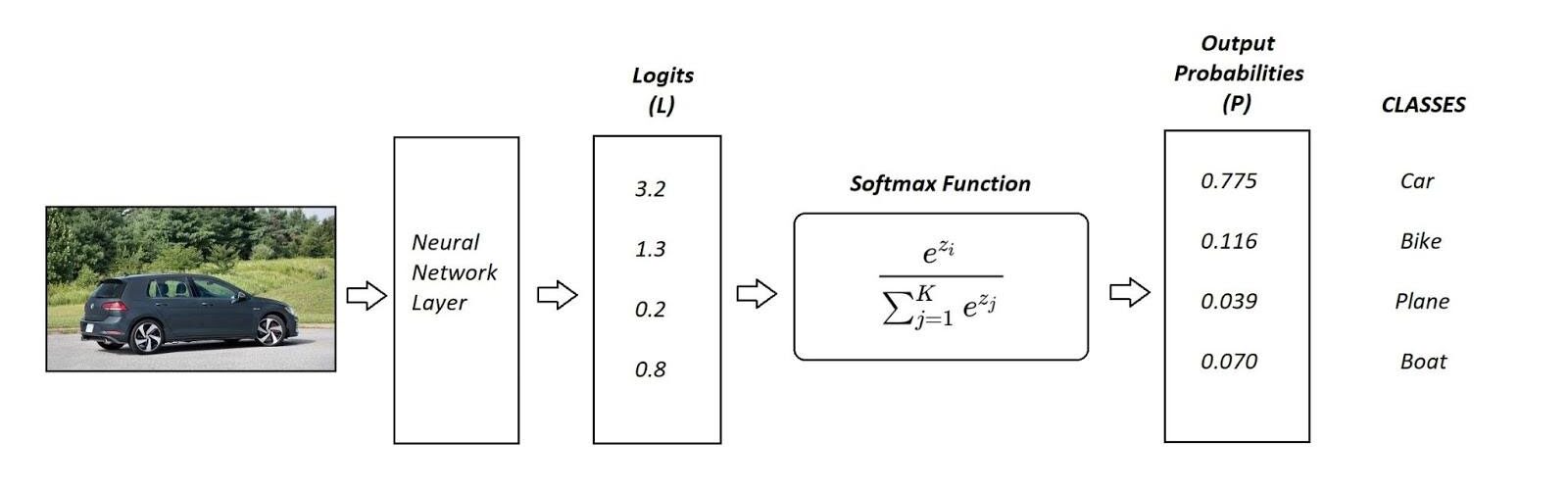
In the illustration above, a Softmax function is used to convert logits into probabilities. The Cross-Entropy takes the output probabilities (P) as input and calculates the distance from the true values.
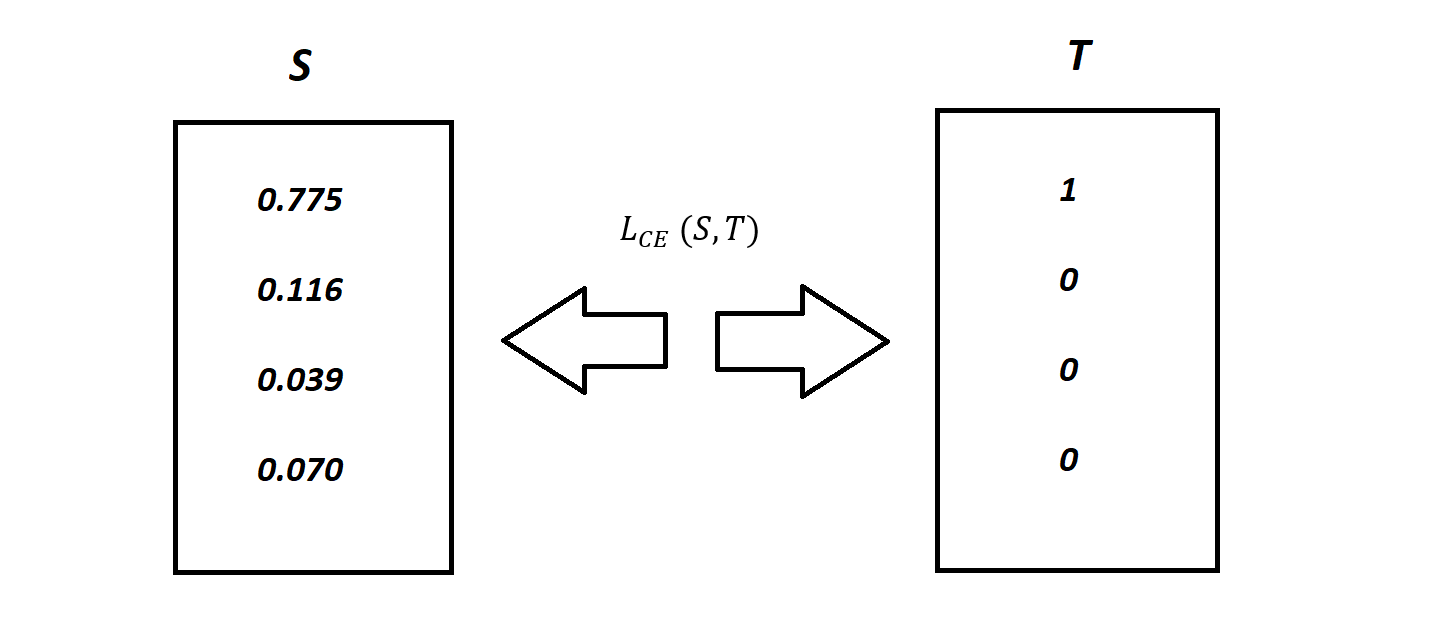
For an aforementioned example the desired truth output is [1,0,0,0] for the class Car but the model generates probability distribution values as [0.775, 0.116, 0.039, 0.070] .To train the model so that it delivers the output with as much proximation as possible to the desired outcome, truth values. During the training phase, the model weights are adjusted several times to minimize the Cross-Entropy loss. This process of adjusting the weights is known as the training phase in Machine Learning, and as the model progresses with the training and the loss starts getting minimized, it is said that the machine is learning.
Entropy - In a Nutshell
Claude Shannon first gave the idea of cross-entropy as a theoretical and mathematical approach to computer science. Before discussing the Cross-Entropy cost function, let find out what entropy is. For function p(x) that denotes probability distribution concerning the random variable X, entropy h(x) is given by a relation:
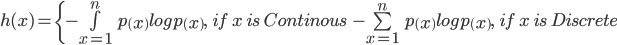
Where log is calculated to base 2. Since log[p(x)]<0, for all p(x), it is taken as negative. p(x) is a probability distribution, and therefore the values range from 0 to 1.
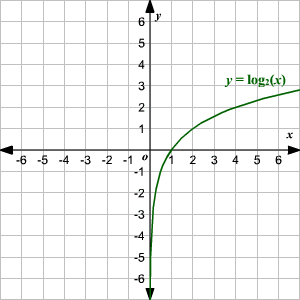
A graph of log(x). For x values ranging from 0 to 1, such that log(x) <0.The entropy is given by h(x) impacts so that with a greater value of h(x), the greater the uncertainty regarding probability distribution, and vice versa.
Example
Consider the following three containers having spheres and cubes.
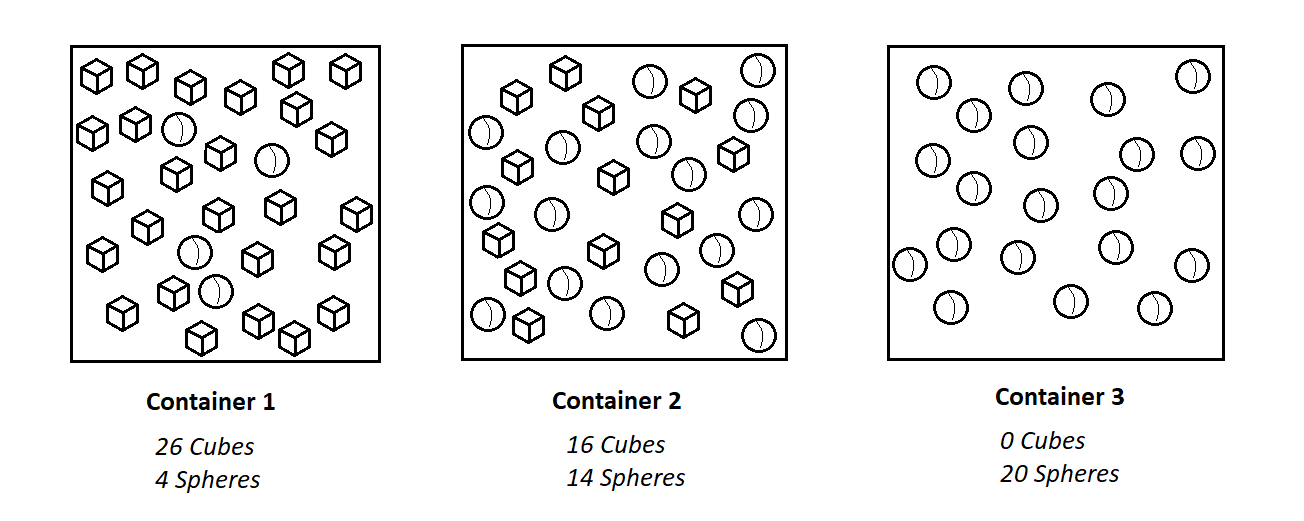
Container 1: The probability of picking a cube is 26 out of 30, and the probability of picking a sphere is 4 out of 30. Due to this, the probability of choosing the cube and not picking the sphere is considered as the more established condition.
Container 2: The probability of picking the sphere is 14 out of 30, and that of the cube is 16/ out of 30. There is almost a 50 percent chance of picking any specific object. Less certainty of picking anyone definite object than the 1st container.
Container 3: An object picked from container 3 is undoubtedly a sphere. The probability of picking a sphere is 1, whereas the probability of picking a triangle is 0. The fact is clear that the shape picked will be a circle.We can cross-check the conclusions above about the certainty of picking a given object by calculating the entropy.
For Container 1:
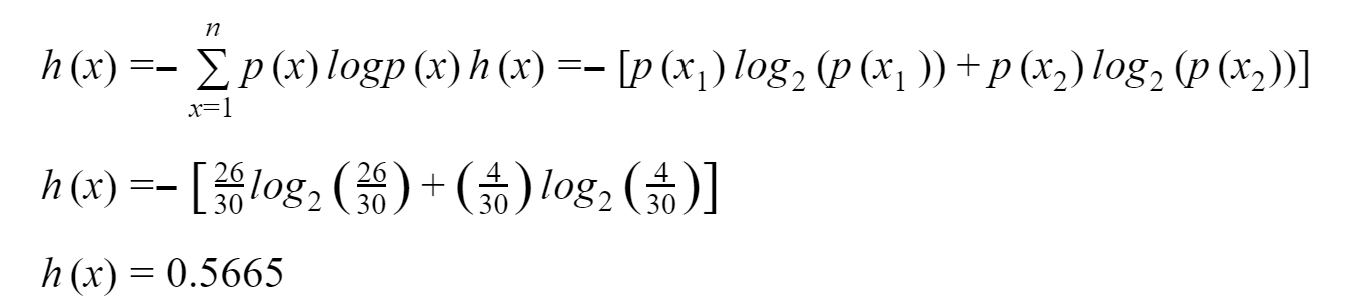
For Container 2:
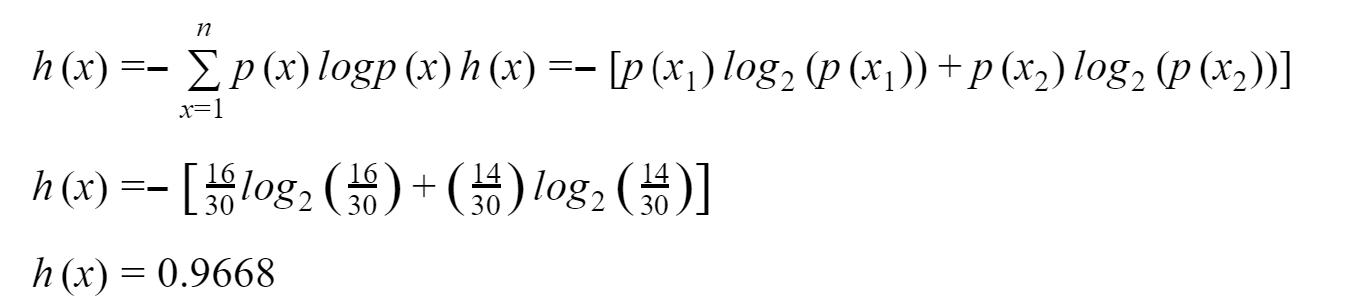
For Container 3:
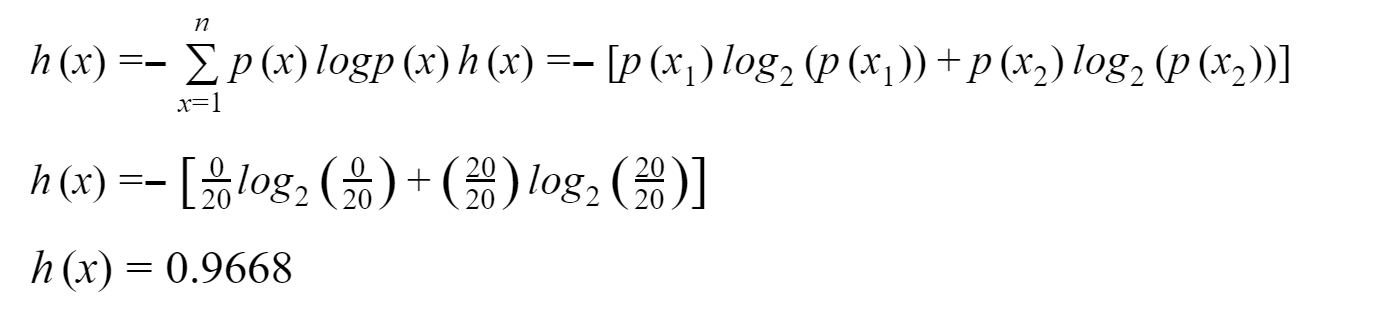
As we have discussed earlier, the entropy for the first container is less than the entropy of the second container. The reason is, the probability of picking a given object is more certain in the case of the 1st container as compared to the 2nd one. The entropy for the 3rd container is 0, which reveals the perfect certainty of the condition.
Cross-Entropy Loss Function - How it Adjusts Weights
For now, you have cracked the riddle about how entropy works. Now it’s time to discuss Cross-Entropy Function in detail. This mathematical representation of entropy is also known as the logarithmic loss or logistic loss. Each predicted class probability is compared against the actual class's desired output (0 or 1). A loss is calculated that is being used to penalize the probability based on its deviation from the actual desired value (truth values).
Also Read: 8 Applications of Data Clustering Algorithms
The penalty is assigned in terms of logarithmic value that provides enough range as large values for deviations nearest to 1 and smaller values for smaller deviations nearest to 0.Cross-entropy loss is used when adjusting model weights during training. The aim is to minimize the loss, i.e., the smaller the loss, the better the model. A perfect model has a cross-entropy loss of 0.
An equation gives Cross-entropy:
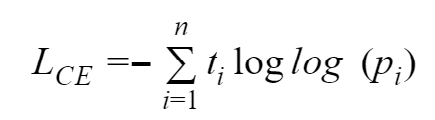
Where n shows the number of available classes, ti is the truth label, and pi is the softmax probability for available classes.
Binary Cross-Entropy Loss
For binary classification, we use binary cross-entropy that is given by a mathematical relation:
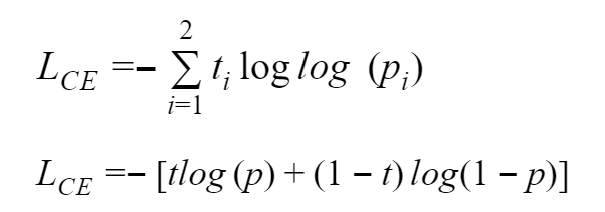
Binary cross-entropy is calculated as the average cross-entropy across all available data points.
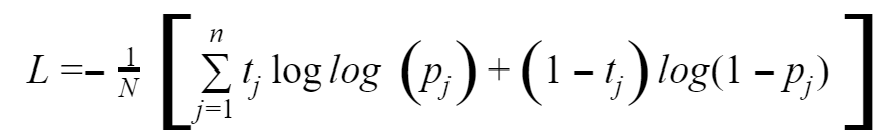
Example
Recall the above classification problem of cars and other transport mediums with the Softmax probabilities (S) and the labels (T). The purpose of the Binary Cross Entropy scheme is to calculate cross-entropy loss provided such information.
The categorical cross-entropy is calculated as:
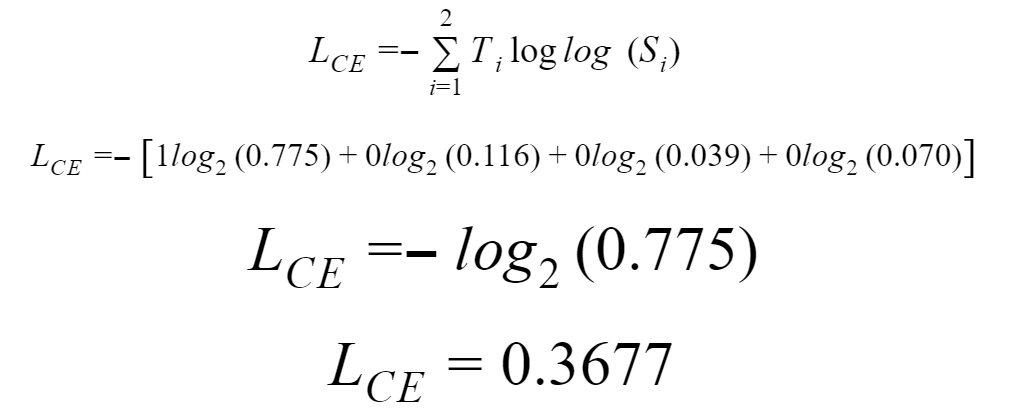
Softmax is a continuously differentiable function that makes it possible to compute the derivative of the loss function concerning every assigned weight in the neural model. This attribute enables the model to adjust the weights following the minimization of the loss function. By doing so, the model pushes the output values close to the true values. Assume that after the repetitive training of the model, the output showcases the following results.
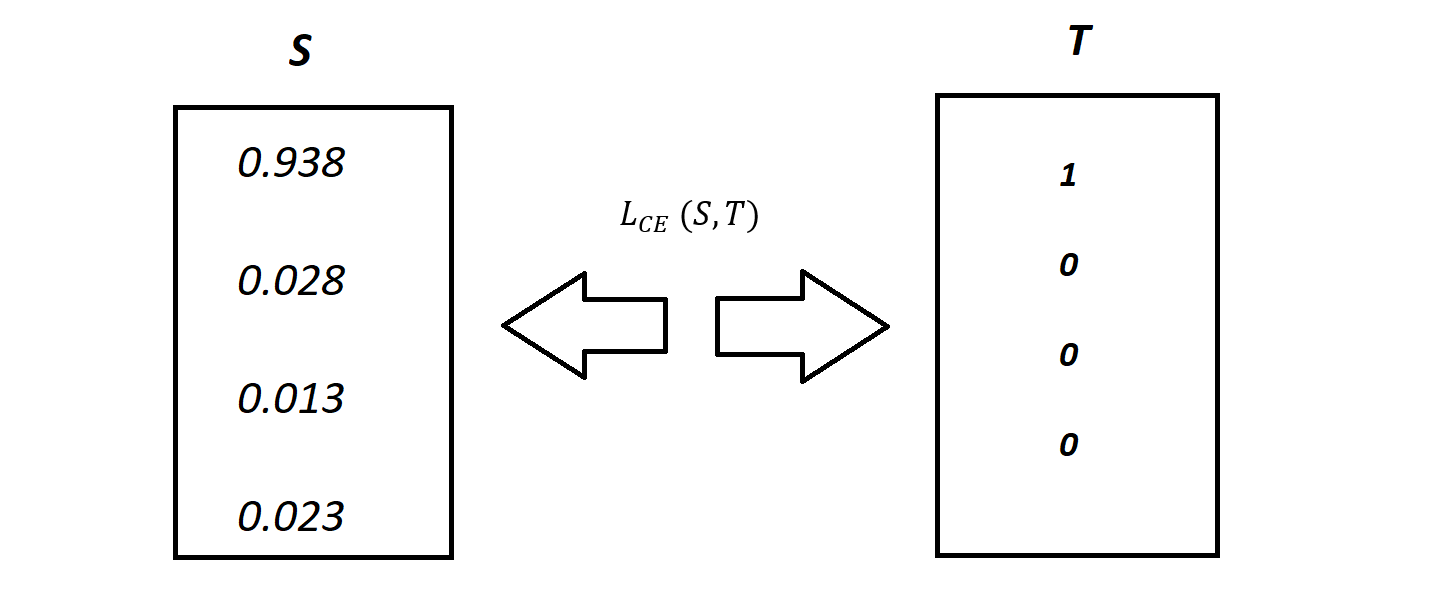
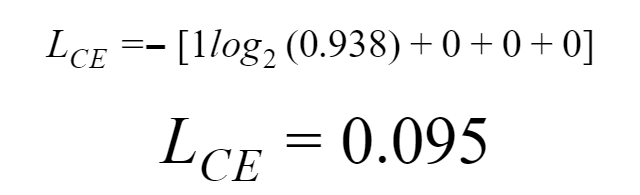
0.095 is less than the previous loss (less difference in softmax value and truth-values that is 0.3677), given that the model is still learning with every cycle. The cycle of adjusting weights to bring output values close to desired or truth values continues until the training phase is completed.
Keras provides the utilities of the following cross-entropy loss functions:
- Binary
- Categorical
- Sparse
Categorical Cross-Entropy and Sparse Categorical Cross-Entropy
Both categorical cross-entropy and sparse categorical cross-entropy loss functions have the same loss function as the aforementioned cross-entropy functions. The only difference between these functions depends on how truth labels are defined. In Categorical cross-entropy, truth labels are encoded as binary odds for instance the truth labels for 3 class problem are given as [1,0,0], [0,1,0] and [0,0,1]. Whereas, in sparse categorical cross-entropy, truth labels are expressed as integers, such as [1], [2], and [3] for the 3-class problems.
Conclusion
Mathematics is the backbone of machine learning algorithms. As we have discussed all the mathematical formulas related to cross-entropy, it reveals that a sound grip over mathematics supports understanding machine learning.


